Overview
What is CLIML?
CLIML is a CLI tool that rapidly automates the creation of powerful supervised learning models:
- Auto-detection for regression/classification tasks.
- Automated hyperparameter tuning and model selection.
- Train models as quickly (or as extensively) as you like.
- Make easy predictions and output them to a CSV file.
- Beautifully formatted
--helpif you get stuck.
Who is CLIML for?
- Anyone who has some data and wants a quick, accessible way to apply ML.
- Data scientists who want to accelerate their ML prototyping workflows.
Installing CLIML
1. Pre-Requisites
- Python >=3.11
- libomp (if using MacOS)
On MacOS, libomp is required for LightGBM models. You can get libomp by running: brew install libomp.
2. Pip Install
Enter the following into the command line in your chosen directory:
$ pip install climl
Using CLIML
1. Getting Data
You can't do machine learning without some properly formatted data.
- Make sure it's a rectangular dataset (like you'd get in Excel).
- Ensure that your dataset has column headers.
- Put the output you want to start predicting in the final column.
- Save your dataset as a CSV file. (Excel coming soon!)
- Navigate to where the file is saved via the command line (
lsandcdare your friends).
That's as complicated as it gets! Now you're ready to do some Machine Learning.
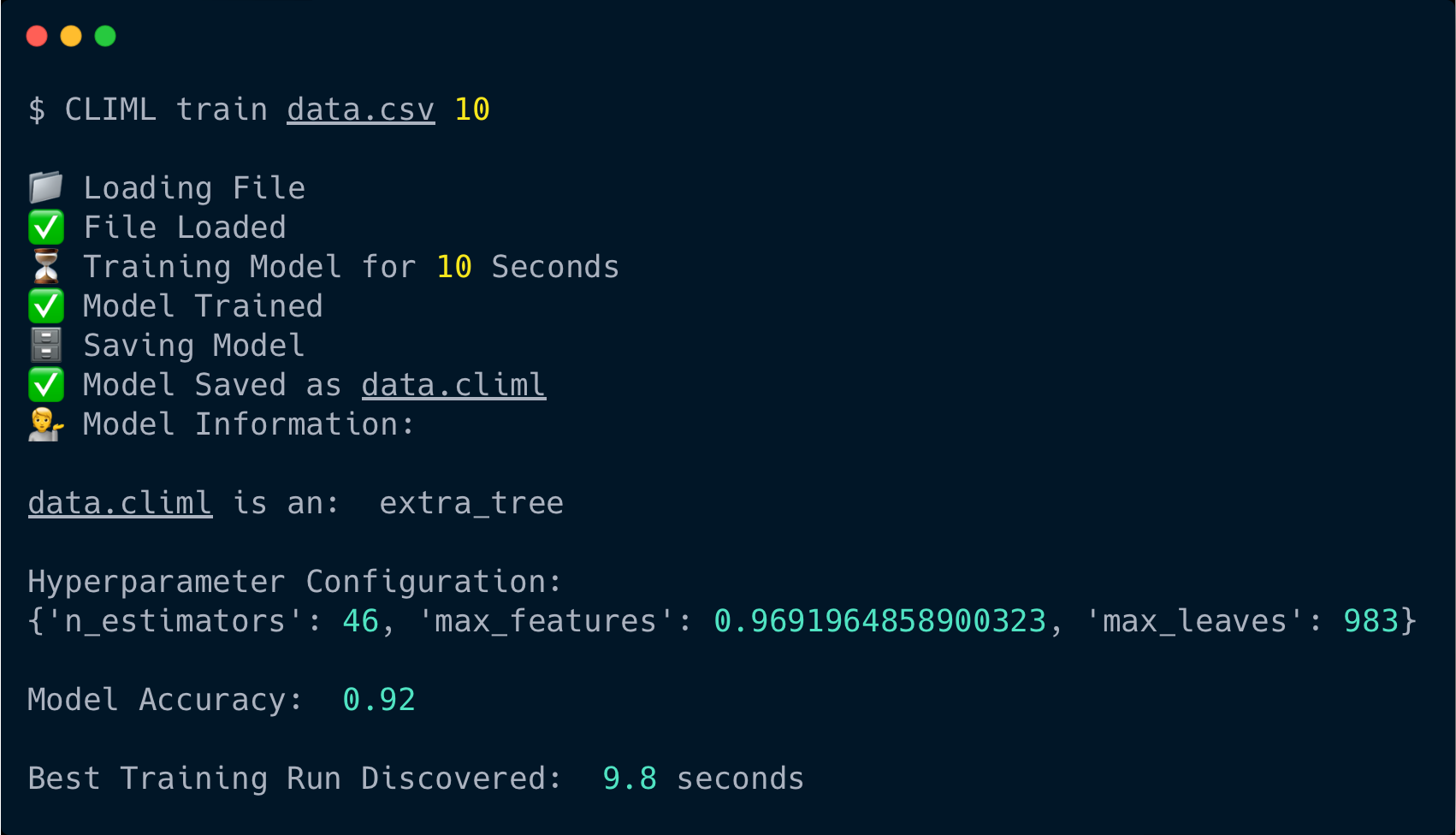
2. Training a Model
You can train a powerful ML model using just four words (in seconds) :
$ climl train dataset.csv num_of_seconds
This will tell CLIML to ...
- Detect whether the final column in
dataset.csvis numerical or categorical. - Begin training multiple regression or classification models, respectively.
- Continue tuning hyperparameters for your specified
num_of_seconds. - Display the most accurate model and its hyperparameters to the terminal.
- Save your model as an
.climlfile.
If you enter ls you'll be able to see your newly trained dataset.climl model!
3. Inspecting a Model
Forgot what type of model you trained? Interested in telling everyone about its hyperparameters? You'll only need three words this time:
$ climl inspect dataset.climl
This will output the model's type, hyperparameters, accuracy, and time taken to discover
4. Making Predictions
Annoyingly you'll need four whole words again.
Firstly, make sure that your things_to_predict.csv file is formatted exactly like the CSV file which model.climl was trained on - just without the final output column!
Then run:
$ climl predict things_to_predict.csv model.climl
This will:
- Display a prediction of the outputs for whatever inputs are in
things_to_predict.csv - Append a new column to
things_to_predict.csv, with the header "Predicted Outputs"
5. Errors and --help
If you enter something incorrect, CLIML is pretty good at telling you why. For instance, if you enter:
$ climl train data.csv
You should see something like this:
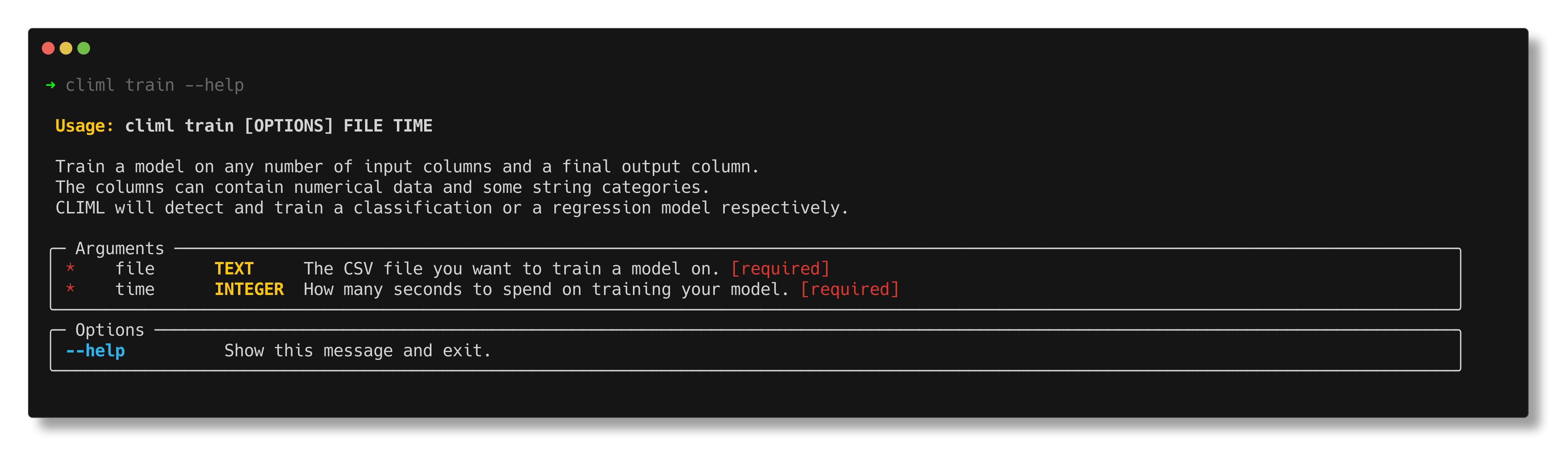 It looks like you didn't specify a training time!
It looks like you didn't specify a training time!
If you're still a bit stuck, you can always enter one of the following:
climl --helpcliml train --helpcliml inspect --helpcliml predict --help
To get something like this:

Roadmap
Here are some things on the roadmap:
- Train and send predictions to an Excel file
- Timeseries problems
- Multi-output models
- Automated data-cleaning
- Plotting functionality
If you particularly need one, drop us an email at the bottom of the page!
FAQs
What models does CLIML train?
CLIML runs its model selection algorithm on: XGBoost, LightGBM, Random Forest, Extra_Tree, Logistic Regressions with L1 and L2 Regularization, CatBoost, KNeighbours
How long to specify for training?
Depending on your dataset, start small (<20 seconds), then lengthen until you notice accuracy starts to taper off or if it's "good enough"!
Do I need a super-powerful computer?
No! CLIML is suited for devices with low computational resource. But there are limits to everything!
Contact
Any questions are very wlecome - please send them to: [email protected]